问题来源于实践,实践是检验真理的唯一标准
分析执行
今日正浏览借鉴别人网站的长处时,发现一站点注册界面没有加验证操作。于是F12,经过再次注册,梳理了注册的整个流程。于是打开PyCharm,代码一顿撸。

发现把浏览器中的头信息全抓过来,换成随机的用户名密码邮箱,发送post请求后,返回的是500。不解,深入研究后发现每次请求返回的500信息页面中,注册表单有个隐藏input输入框,并且名称很可疑,竟然叫_token,而且赋了value值。
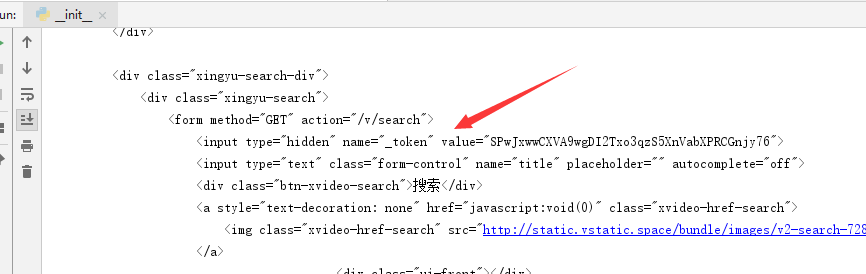
想必这就是每次注册不能一样的token信息吧,于是换在头信息和注册form表单提交信息中,再次请求,发现是可行的,返回了{“result”:true,”data”:””}信息,到页面登陆也是ok的。接着再请求一次就是返回的500了,而且返回的500页面,input的value值也更新了,于是想,能不能利用爬虫把这500页面的input值获取,放到新的注册接口中请求中在此注册呢,于是代码又是一顿撸。
获取token—>更新token信息—>请求注册接口。最外层加了个for循环,循环100次,也成功注册了100个账号。页面随便取出一个账号登陆也没毛病

总结积累
代码实现
1 | from urllib import request |

